AI Model Quantization: Leaner, faster, cheaper inference.
Transforming high-precision weights into compact, efficient formats can revolutionize speed, reduce costs, and maintain accuracy.
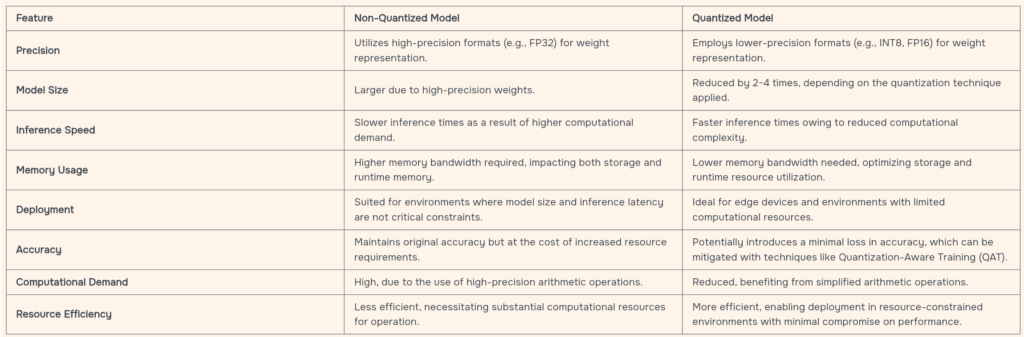
– At its core, model quantization is a technique aimed at reducing the size of a deep learning model. This is achieved by adjusting the model’s weights from high-precision formats (like 32-bit floats) to lower-precision formats (such as 16-bit or 8-bit). The primary goal here is to strike a balance between efficiency and performance.
– The rationale behind model quantization is straightforward: smaller models demand less computational power and storage space. This directly translates into faster processing times and reduced operational costs, particularly beneficial for deployments in cloud and edge computing environments.
– There are two principal strategies in the realm of model quantization: Post-Training Quantization (PTQ) and Quantization-Aware Training (QAT). PTQ applies quantization after the model has been fully trained, whereas QAT integrates quantization into the training process itself, anticipating and adjusting for the potential impact on the model’s accuracy.
– While quantization holds the promise of smaller, more efficient models, it’s not without its challenges. The primary concern here is the potential loss of accuracy. Models, especially those operating in precision-critical applications, can suffer performance degradation if not properly quantized.
– Addressing these challenges, selective quantization emerges as a nuanced approach. It involves analyzing the model to identify which components can be quantized without significantly impacting overall performance. This selective process ensures that the benefits of quantization are realized while minimizing adverse effects on model accuracy.
– Best practices in model quantization involve a combination of techniques and considerations. These include choosing the right quantization method, conducting thorough testing to assess the impact on model accuracy, and employing strategies such as per-channel scaling or using calibration methods (max, entropy, percentile) to fine-tune the quantization process.
Model quantization represents a compelling pathway to making deep learning models more accessible and cost-effective, particularly for applications requiring deployment across a wide range of devices and platforms.
Brought to you by Veso AI Research.